Combining automatic and manual sense linking of dictionaries
Sense-linked dictionaries promise to significantly enrich lexical resources, among other things by enabling the creation of new multilingual content. Unfortunately, human linking is prohibitively expensive, and automated linking, while encouraging in research, fails to deliver production-quality results. Therefore, as part of the Prêt-à-LLOD project, we at the Oxford University Press have developed a pipeline for semi-automatically linking dictionaries on the sense level, ensuring both high quality and efficiency. The pipeline comprises a three-step process:
- A supervised machine learning algorithm combined with a statistically based classification layer predicts a binary class (link or non-link) for all possible sense pairs between two dictionaries.
- Relative frequency measures are used to estimate the probability that a sense pair’s prediction is correct. These estimates serve to provide general quality estimates in terms of precision and recall, and they enable the filtering of predictions by certainty.
- The filtering from the second step is used to identify a subset of sense pairs for further inspection by human editors. The option of human editorial input adds a dimension to the receiver operating characteristic (ROC) curve that leads to a new trade-off between quality (precision and recall) and resources (person-hours). This trade-off allows flexible prioritization on a project-by-project basis, which is essential for implementing sense linking in the business context.
Where does linked lexical content fit within the industry? Crucially, linking lexical data creates business opportunities. For one, linked data can expedite internal processes. For instance, through improved data integration editors can research, consult, and compare various resources more efficiently. Additionally, linked data can enable creation of new products. By creating a holistic structure of linked data, we can provide data and products that integrate content from diverse resources. The main obstacle to linking data is the immense costs associated with it, both in terms of money and time. Manually linking two dictionaries might take at least 3000 person-hours, costing well over £50,000. Apart from cost, another important factor to consider in the business context is the quality of the links. That is, what is our confidence that a given sense link is correct?
How many true sense links do we expect to miss? Quantifying the expected quality of sense links is crucial in helping us identify the opportunities and limitations of applying linked data in the business context. Furthermore, for different business requirements, the expectations for the completeness and the correctness of sense links can differ. If we have a human-facing product, such as an online dictionary displaying content from several linked dictionaries, we need to prioritize the correctness of the links, because any false link will have a stronger negative impact on the user experience than a missing link. Conversely, completeness is a higher priority than correctness for some other uses of linked data. For instance, an internal tool for editors’ exploratory research needs to provide as complete a set of links as possible. In this case, incorrect links merely slow down the process while missing links obstruct it and render it incomplete.
Therefore, correctness takes lower priority here than completeness. Lastly, for projects like the creation of a new dictionary, we require high quality both in terms of correctness and completeness. Even in these cases, semi-automated linking can yield resource savings, as of the sense pairs can be classified automatically with very high certainty.
These examples show that we need to be able to adjust the sense linking parameters on a project-by-project basis, such that we can meet the quality requirements while equally satisfying the resource constraints of a given project. Notably, it is not only the absolute quality of automatic linking that matters here but also the control we have over specifying the level of quality. This control makes possible the full leveraging of automatic and manual linking to optimally meet business demands.
Workflow and Use Cases
Meeting the business demands outlined above in practice requires three major mechanisms, which we summarize here as three different use cases. These use cases build on each other, that is, for each use case, we add a step in the pipeline: In the first case, we link dictionaries fully automatically and further provide quality estimates. In the second case, we prioritize different kinds of quality (precision or recall) while still linking the dictionaries fully automatically. In the third and final case, we first set our quality requirements and then optimize efficiency by fulfilling these requirements through semi-automatically linking the dictionaries. To do so, we leverage human annotations where necessary to ensure we can attain the desired quality of links.
Use case #1: Automated linking with quality estimates
The first use case is the fully automatic linking of a new bilingual dictionary to a monolingual dictionary.
Besides the absolute links, we also want proper estimates of the quality of the new linked dictionary, so that we understand the opportunities and limitations of using the linked data in our projects. We get these probability estimates for each possible sense pair (link or non-link). We can then use the probability scores to calculate the number of true positives, true negatives, false positives, and false negatives that we expect in a set of newly predicted sense pairs. This calculation, in turn, allows us to estimate statistics like precision and recall for the full automatically linked dictionary or any subset thereof, without the need for additional manual annotations of the new data.
The ability to automatically add quality estimates when linking a new dictionary pair saves resources since we no longer have to rely on new manual annotations each time we want to estimate the quality of newly linked dictionary content. Furthermore, it provides us with an immediate evaluation regarding the feasibility of automatically linking the new dictionary. This evaluation allows us to make decisions around which business cases and projects the linked dictionaries can be used for.
Use case #2: Automated linking with prioritization
The second use case concerns the balancing of different quality requirements, namely the trade-off between precision and recall.
As mentioned previously, different business contexts may require different quality prioritization. For some applications of linked dictionary content, especially those involving direct human consumption, precision takes precedence over recall. That is, the correctness of the created links is more important than their coverage. In other scenarios, like exploratory research or some machine applications, it may be the other way around. Therefore, we want to be able to calibrate the algorithm’s predictive threshold, trading off precision for recall or vice versa.
Figure 1 shows how the trade-off works in practice. The sense pairs are ordered by their likelihood of being a true sense link, and the linking threshold is adjusted to link more or fewer sense pairs. Linking fewer sense pairs results in better precision at the cost of recall while linking more sense pairs improves recall at the cost of precision. With all possible sense pairs considered, there are generally more true non-links than true links. This imbalance means that it is possible to reach high levels of precision while keeping recall reasonable. However, aiming for high recall tends to result in very low precision levels. As such, quality prioritization through threshold adjustments works well for high precision requirements, but less so for high recall requirements. Achieving high recall at reasonable precision levels necessitates human input, as discussed in use case #1.
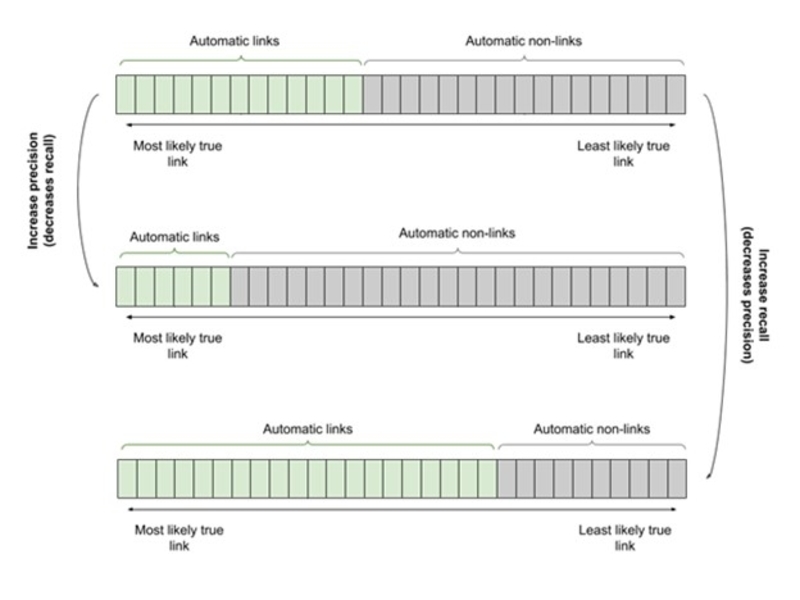 Figure 1: Trade-off between precision and recall for fully automated linking.
Figure 1: Trade-off between precision and recall for fully automated linking.
Use case #3: Semi-automated linking for quality determination
The third and final use case extends the automated sense linking process to incorporate the expertise of in-house lexicographers.
This use case is of special interest for OUP. Since a high quality standard is essential to our data linking efforts, we need to be able to augment automated linking with the expertise of domain experts. We add a threshold to optimally divide the sense pairs into automatic links, automatic non-links, and human verification needed to meet quality requirements efficiently through semi-automated linking. We assume that human annotations are infallible . However, since not all sense pairs annotated manually are true sense links, we again use the sense pairs’ probabilities to calculate the expected number of true links and non-links among the human-annotated sense pairs. Doing so allows us to calculate precision and recall estimates for this use case as well.
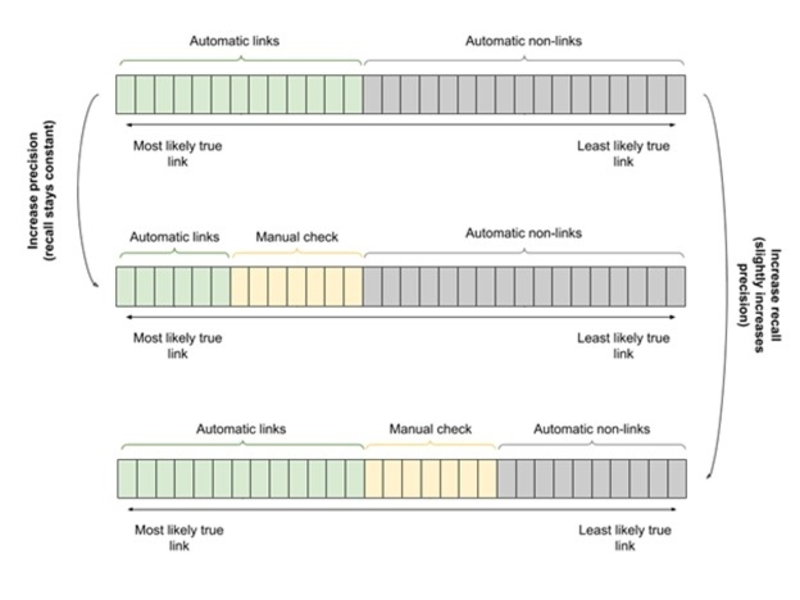 Figure 2: Trade-off between precision, recall, and person-hours for semi-automated linking.
Figure 2: Trade-off between precision, recall, and person-hours for semi-automated linking.
Figure 2 visualizes the new trade-off between precision, recall, and person-hours.
Naturally, the higher the quality requirements, the more human editing is needed. Expert in-house lexicographers check the sense pairs automatically identified as requiring human verification. The result is a set of automatic links, human-edited links, automatic non-links, and human-edited non-links. The links, automatic and human-edited, are then integrated into the data model.
Results
When linking a new dictionary, we can decide how much of the dictionary we want to link automatically and how much we want to verify with human editors. As discussed in previous sections, this decision depends on the business and project requirements and constraints. Using the training data for the sense linking pipeline (six bilingual dictionaries manually linked to a monolingual dictionary), we show how different percentages of human-annotated sense pairs affect the quality of the sense links. Figure 3 plots receiver operating characteristic (ROC) curves for different degrees of automation. It shows that even low levels of human annotation significantly improve linking, while manually annotating half the sense pairs leads to near-perfect results. Accordingly, even with high quality requirements, large parts of the dictionary linking process can be automated. Conversely, even quite limited editorial input can increase the quality of automatically linked dictionaries.
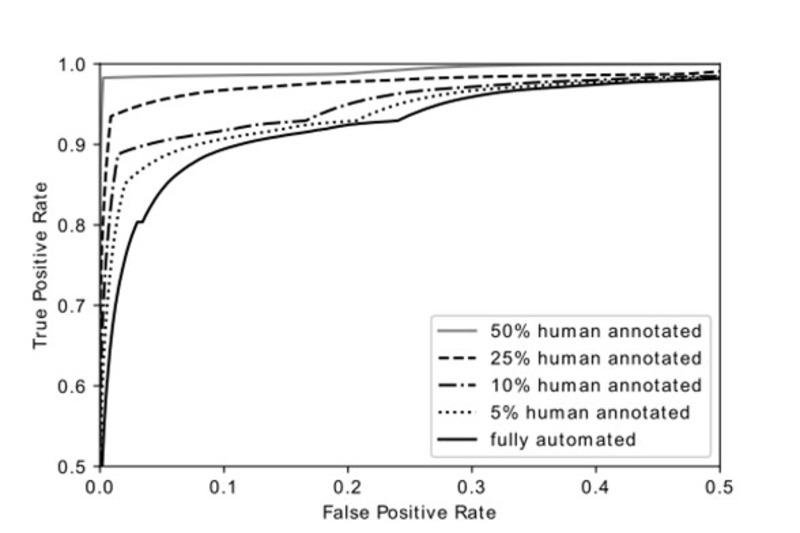 Figure 3: Receiver operating characteristic (ROC) curves for semi-automated dictionary sense linking.
Figure 3: Receiver operating characteristic (ROC) curves for semi-automated dictionary sense linking.
Conclusion
The system for cross-dictionary sense linking described provides a principled way of meeting various quality requirements and resource constraints that OUP faces in the business world. The additions to the initial algorithm for automated sense linking are crucial in addressing our varying expectations and specifications of quality for different products and use cases. Furthermore, the resources available differ on a project-to-project basis, making it necessary to calibrate the involvement of lexicographers and editors. As such, the whole linking system enables the combination of automation with editorial expertise, resulting in a process that supports both efficiency and high quality.
Relevant Publications
Kouvara, E., Gonzàlez, M., Grosse, J. and Saurí, R., 2020. Determining Differences of Granularity between Cross-Dictionary Linked Senses. [online] Democritus University of Thrace, pp.109-118. Available at: https://euralex2020.gr/wp-content/uploads/2021/04/EURALEX2020_ProceedingsBook-Vol1-Preview.pdf [Accessed 13 July 2021].
Grosse, J. and Saurí, R., 2020. Principled Quality Estimation for Dictionary Sense Linking. [online] Democritus University of Thrace, pp.101-108. Available at: https://euralex2020.gr/wp-content/uploads/2021/04/EURALEX2020_ProceedingsBook-Vol1-Preview.pdf [Accessed 13 July 2021].
Gonzàlez, M. and Saurí, R., 2020. XD-AT: A Cross-Dictionary Annotation Tool. [online] Democritus University of Thrace, pp.503-508. Available at: https://euralex2020.gr/wp-content/uploads/2021/04/EURALEX2020_ProceedingsBook-Vol1-Preview.pdf [Accessed 13 July 2021].